阅读论文:View Independent Generative Adversarial Network for Novel View Synthesis
VI-GAN,视角生成,ICCV2019
问题:该问题一般有两种方法:基于几何的方法和基于学习的方法。
(1)基于几何的方法一般是先从二维图像推测三维图形,再抓取另一视角的二维图像。然而这种方法本身是 ill-posed的,它只适用于特定场景。而且三维的获取很困难。
(2)基于学习的方法中,GAN通常将相机参数离散为一个固定长度的向量,这会丢失相机参数里的3d信息。
解决:在基于学习的方法基础上,隐式地推断出3d知识。即编码器提取代表物体固有属性的view-independent feature,解码器根据特征和指定的相机pose合成图像。
结构:编码器,解码器,embedding网络(MD-多层感知机),双判别器。
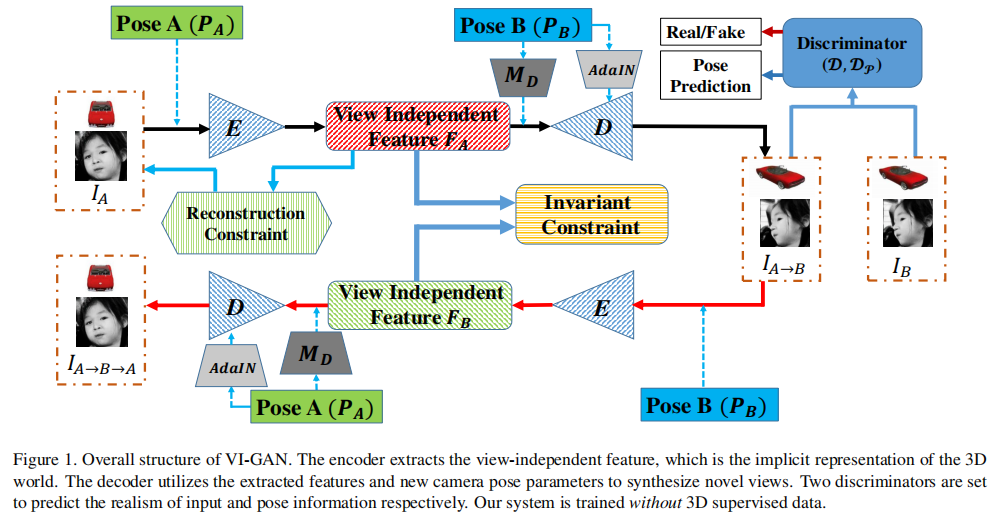
编码器中:为了基于二维图像推断三维相关知识,编码器E需要隐式地将二维图像注册到潜在的三维模型中。在这方面,二维图像的位置信息是重要的。然而,由于空间不变性,CNN只感知局部区域而不考虑位置。因此,利用CoordConv代替传统卷积,通过将像素位置作为两个额外的通道连接到特征映射中来解决这个问题。
损失:一个视角独立的损失项、一系列图像重建损失项、一个GAN损失项和一个姿态预测损失项。
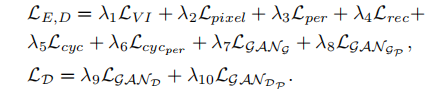
View-independent Loss:不同视角的同一物体的固有属性特征要一致。
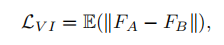
Image-reconstruction Loss:针对一次转换&两次转换(循环)的像素损失和感知损失,identity loss。
GAN Loss: WGAN-GP.
Pose Prediction Loss:利用另一个判别器来姿势预测,确保与目标姿势一致。
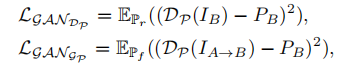
数据集:ShapeNet, Multi-PIE and 300W-LP。
实验设置:消融实验,确定编码的特征是否有3D信息( 3D face landmark estimation实验:一种是从头训练,一种利用VI-GAN作为预训练),对比实验(离散旋转,连续旋转)