阅读论文:Unsupervised multi-domain multimodal image-to-image translation with explicit domain-constrained disentanglement
DCMIT,多域,多模态,无监督。
图像-图像翻译问题:1)无成对训练数据。2)来自单个输入图像的多个可能输出的模糊性。3)缺乏对使用单一网络进行多域翻译的同时训练。
隐式解缠学习问题:部分情况下,混淆内容和风格。
相关工作: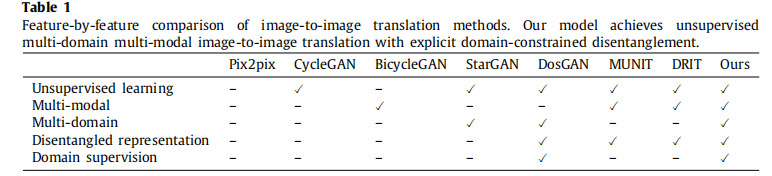
域内监督和域间监督: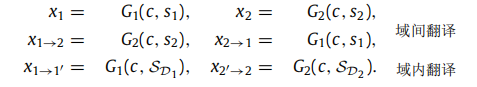
域样式表示提取器的预训练:给定来自n个不同领域的图像,我们通过切换来自同一领域的图像的样式代码来训练一个CNN。目的是为了学习特定域的样式表示,并正确地对图像的域进行分类。然后这个预训练好的模型被用作域间翻译的显式域监督。
框架: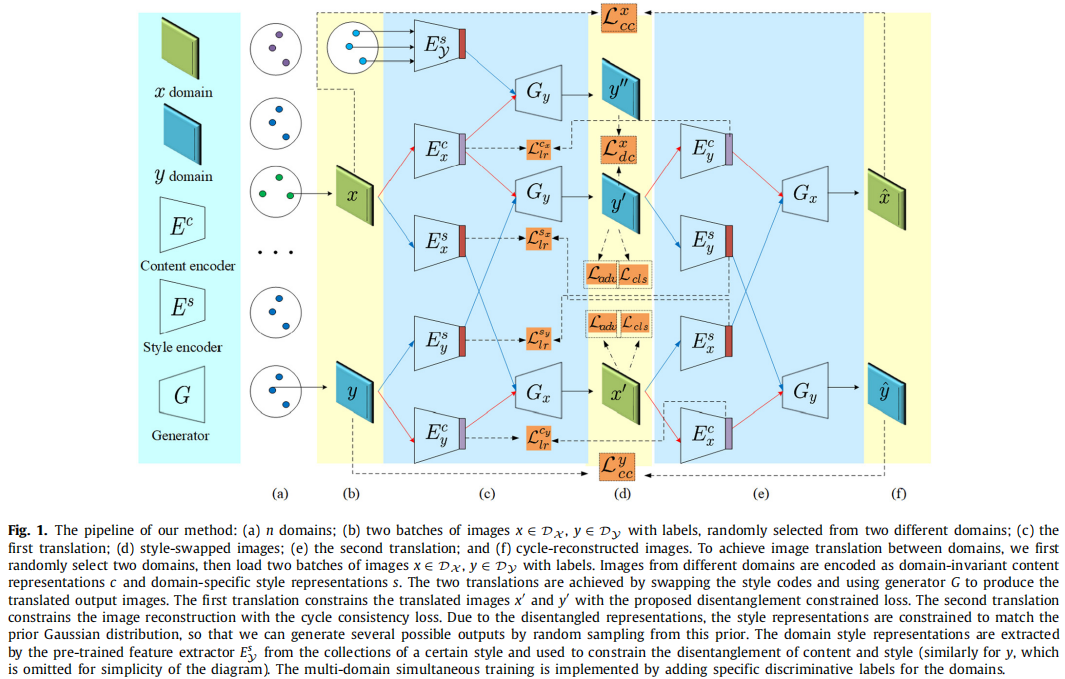
结构:内容编码器,样式编码器,解码器。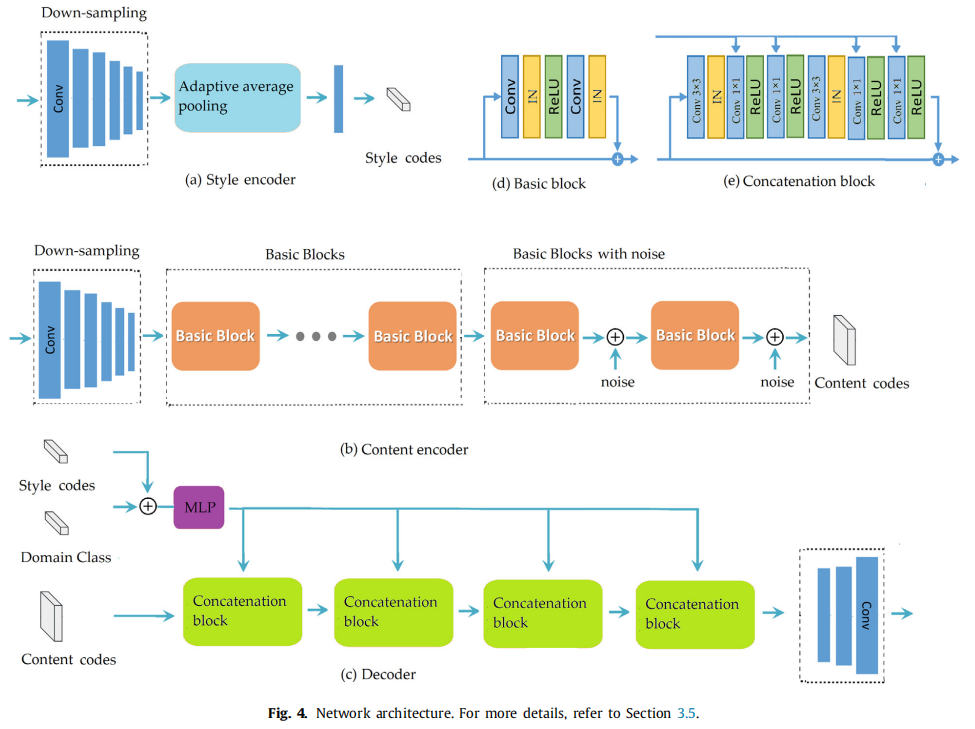 内容编码器:IN。样式编码器:无IN,因为IN会移除包含重要样式信息的原始特征的均值和方差。解码器:AdaIN。
内容编码器:IN。样式编码器:无IN,因为IN会移除包含重要样式信息的原始特征的均值和方差。解码器:AdaIN。
域样式表示提取器,判别器和域分类器:
损失:
Self-reconstruction loss: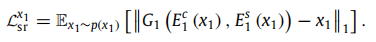
Image reconstruction loss:两步。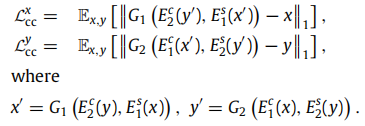
Disentanglement constrained loss:利用域信息并明确地约束解纠缠。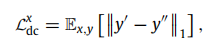
Latent reconstruction loss: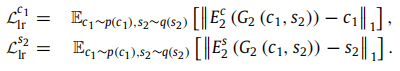
Distribution matching loss:使样式编码接近于先验的高斯分布。MMD。
Domain classification loss: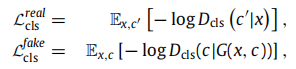 域分类器与域样式表示提取器一起预训练。
域分类器与域样式表示提取器一起预训练。
Adversarial loss:LS。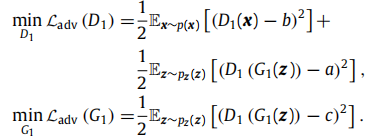
编码,解码,判别器总损失:(14-15)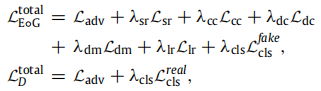
域样式表示提取器:(16-17)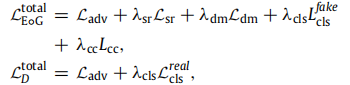
算法:
实验:艺术,天气,季节。边缘→鞋,边缘→手袋。
未来工作:扩展到多退化图像恢复。