阅读论文:Three-view generation based on a single front view image for car
多视角,2020
问题:输入图像没有包含足够的像素信息时,生成的图像质量不佳。
流程:粗粒度视图生成(信息约束网络)--->细粒度视图生成
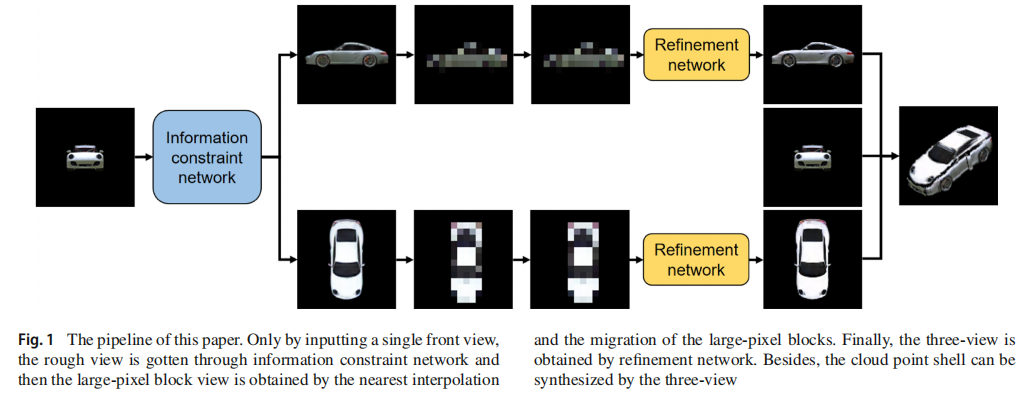
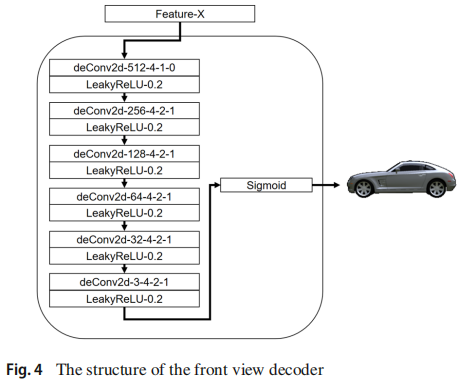
信息约束网络:三个端到端生成网络(编解码网络):左视角生成,顶视角生成,前视角生成。相互约束。
损失函数:L1和感知损失
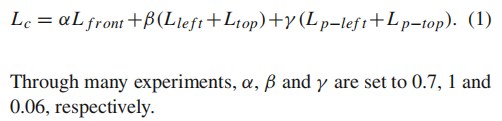
改进视角生成:
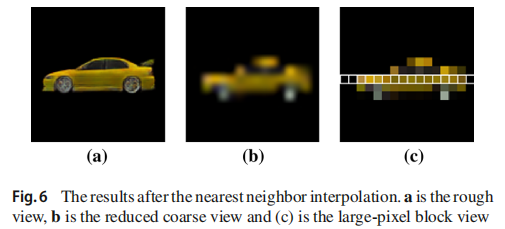
大像素块表征:在缩放过程中,使用最近邻插值对粗糙视图进行缩放,使粗糙视图中的一些模糊像素与其他像素合并成一个大像素块。128×128-->16×16-->128×128(每行16个大像素块)
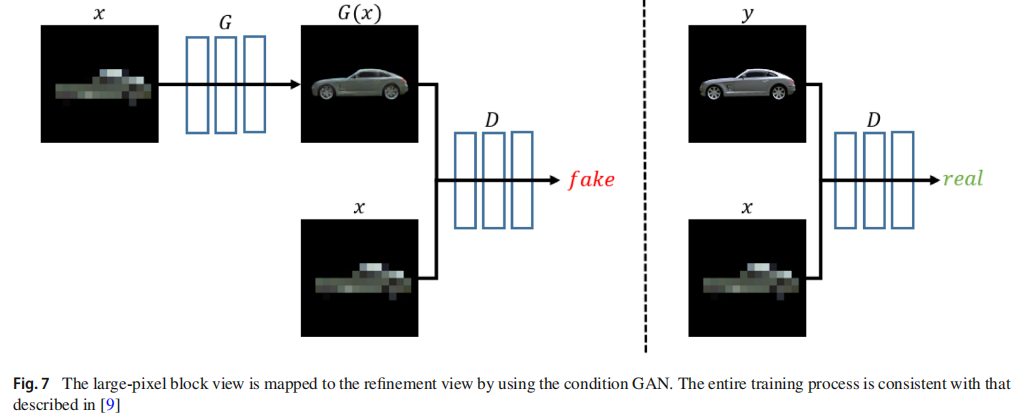
细化网络:pix2pix,判别器最后一层改全连接层,LS loss。
损失函数:系数:100,0.06
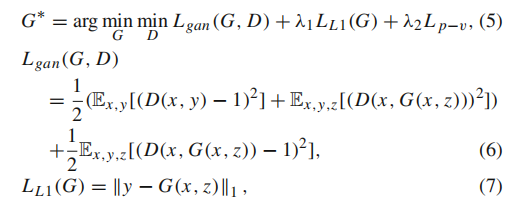
大像素块迁移:我们将一些大像素块从训练集迁移到测试集,以提高视觉效果。SSIM用于从训练集中找到最接近大像素块视图A的大像素块视图B,然后根据颜色差异将合格的大像素块从B迁移到A。

数据集:ShapeNet中的车类。
对比方法:L1,AFN,TVSN,TBN
合成点云外壳:我们找到了三视图的最小包彩色图像和相应的二进制图像,并使用它们来构建一个点云壳。
