阅读论文:Taming Transformers for High-Resolution Image Synthesis
VQGAN,transformer+GAN
代码:https://compvis.github.io/taming-transformers/
问题:卷积只是局部信息,transformer有长依赖关系,但没办法计算高分辨率图像。于是考虑两者结合。
模型与架构:
流程:使用卷积方法来有效地学习上下文丰富的视觉部分的codebook,然后,学习它们的全局组成的模型。
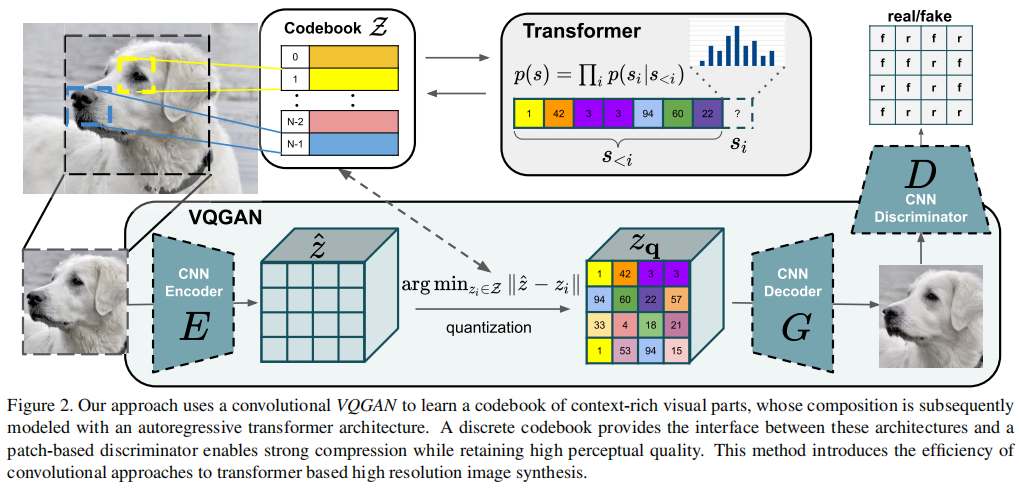

判别器:PatchGAN。
学习codebook:
图像x先经过编码器E,得到,然后经过逐元素的量化:
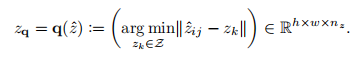
最后经过解码器G,得到生成图像。
损失:
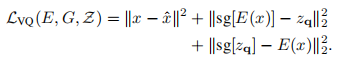
sg[]:停止梯度操作。见VQVAE。
Learning a Perceptually Rich Codebook:
为了学习丰富的codebook,以往的基于L2的重构损失现在替换为感知损失和对抗损失的加权和。
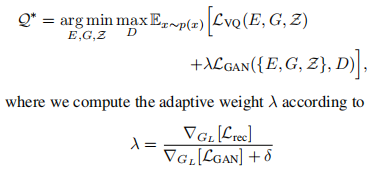
用transformer学习图像组成:
量化后的,等价于s在codebook中的索引,即最大似然函数:
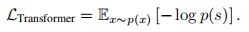
实验:
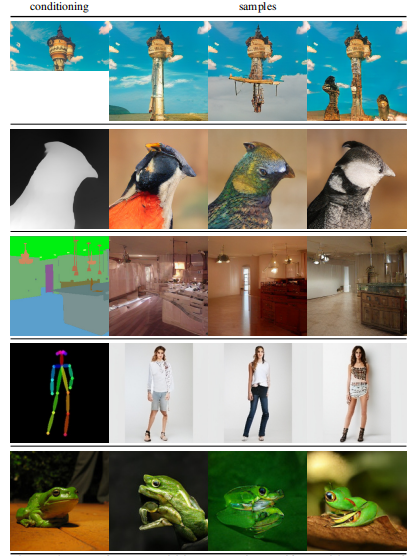
能完成有条件的和没有条件的图像合成任务,因此可作为一种统一的图像合成架构。
后续:
CLIP+VQGAN,让CLIP提供文本和作为一个监督信息。