阅读论文:StarGAN v2: Diverse Image Synthesis for Multiple Domains
StarGAN V2,多域生成,CVPR2020.
代码:https://github.com/clovaai/stargan-v2
问题:好的图像-图像翻译模型需要满足生成图像多样性和多域上有可伸缩性。但已存在的方法只能解决其中之一的问题,该方法可同时满足以上两个条件。
StarGAN问题:仍是学习每个域的确定性映射,它不能捕捉数据分布的多模态性质。这一限制来自每个域都由预定的标签表示的事实。生成器接收一个固定的标签(例如,one-hot向量)作为输入,因此它不可避免地在给定一个源图像时,支持每个域导出相同的输出。
网络:生成器,映射网络,样式编码,判别器
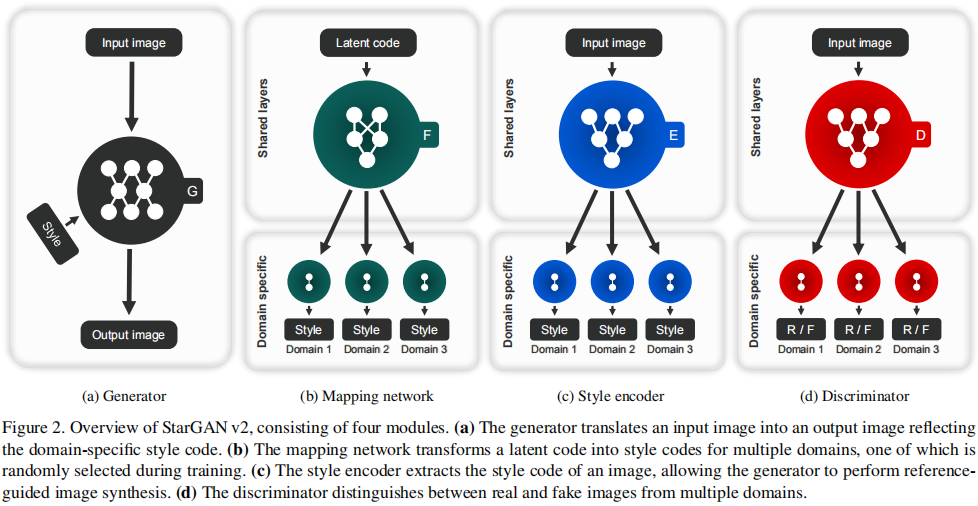
生成器:,输入图像,域特定样式编码(来自映射网络F,或样式编码器E)。使用AdaIN注射到G。s消除了域标签的必要性。
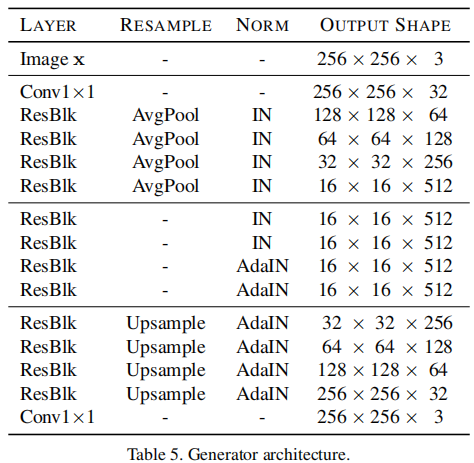
映射网络:,F是一个MLP,有多个输出,对应提供多个域的样式编码。无像素级和特征级归一化。
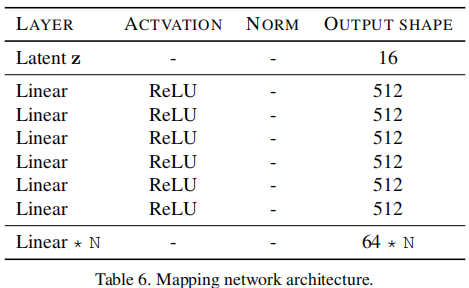
样式编码:,x是参考图像。
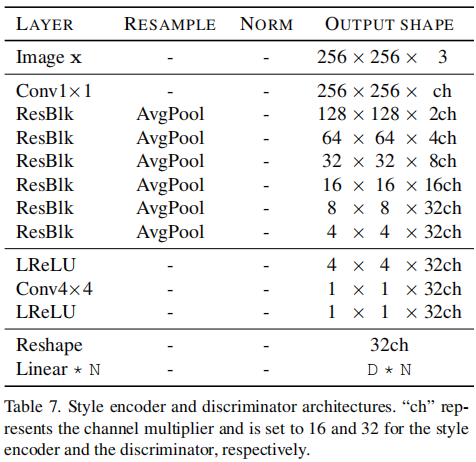
判别器:一个多任务判别器,可以转换全局结构。与样式编码结构同,如下:
损失:对抗损失,样式重构,样式多样,保留原特征(循环一致)
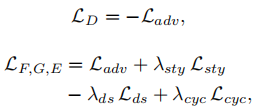
对抗损失:
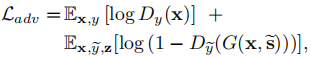
样式重构:
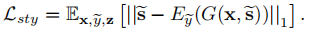
样式多样:最大化下式
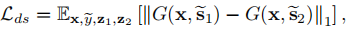
保留原特征:
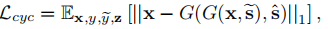
数据集:CelebA-HQ, AFHQ
评估指标:FID,LPIPS,AMT
效果:可以合成反映参考图像不同风格的图像,包括发型,化妆,胡须和年龄,而不损害源特征。结果图像跟随参考图像的品种和头发,保持源图像的姿态。
对比方法:MUNIT,DRIT,MSGAN。缺点:对比方法缺乏多样性,遭受模式崩溃,且很难改变全局上的特征。
讨论StarGAN V2成功的原因:
(1)遵循StyleGAN的洞察力,我们的风格空间是由高斯分布的非线性变换产生的。与假设固定的先验分布相比,这为我们的模型提供了更多的灵活性。
(2)样式编码是由多分支编码器和映射网络单独生成的。通过这样做,我们的生成器只能专注于使用样式编码,它的特定领域的信息已经由编码器或映射网络处理。
(3)我们的模块受益于充分利用来自多个领域的训练数据。通过设计,每个模块的共享部分应该学习区域不变特征,从而产生正则化效果鼓励对未见样本进行更好的泛化。
