阅读论文:Monocular Neural Image Based Rendering with Continuous View Control
2019ICCV,连续视角。
代码:https://github.com/xuchen-ethz/continuous_view_synthesis
以往的方法:直接合成目标视图中的像素或预测流映射以将输入像素扭曲到输出。
问题:过拟合,泛化性差。
几何感知网络:3D转换自编码器(TAE),自监督深度图预测,深度图投影,外观扭曲。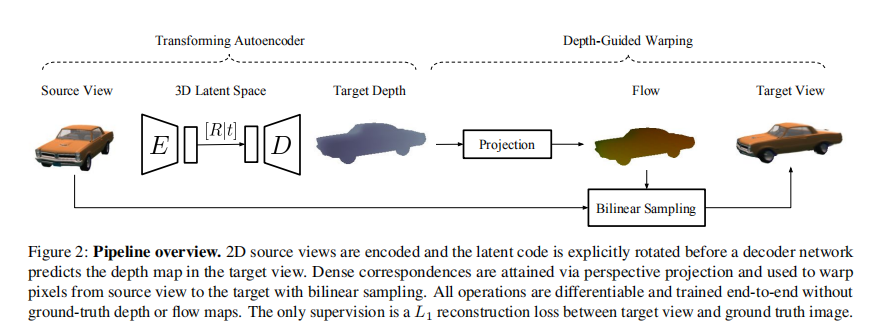
转换自编码器:TAE模块包括编码、向量重塑、矩阵乘法和解码函数。
深度引导下的外观映射:
建立对应关系: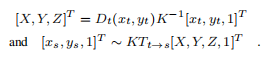
是描述沿两个轴和图像中心的归一化焦距的相机固有矩阵。
外观扭曲:传播纹理和局部细节。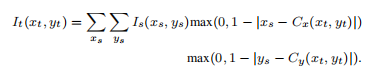
训练:网络中所有步骤均可微,且只有TAE模块包含可训练的参数。重构损失:预测的目标视角和GT图像之间的L1损失。
数据集:Shapenet,KITTI。
指标:L1,SSIM,阈值δ(确认)下的正确性百分比,旋转错误和翻译错误(如下)。
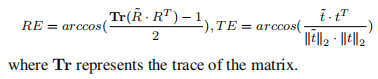
比较结果: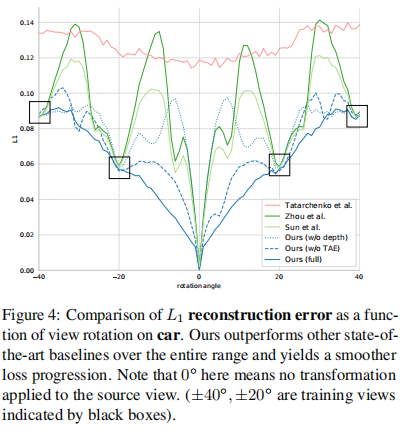
其他实验:深度和流场评估,潜在的空间分析,扩展到看不见的数据。