阅读论文:Informative Sample Mining Network for Multi-Domain Image-to-Image Translation
INIT,多域,ECCV2020.
问题:large domain variations。large semantic discrepancies。 large gap between the source and the target domain。有些样本没用,反而阻碍训练进程。
解决:Adversarial Importance Weighting(AIW)、Multi-hop Sample Training(MST)
度量学习:在embedding空间缩短相似样本距离,扩大不同的样本距离。主要是在损失和样本选择策略上改进。其中,常见损失:constrastive loss和triplet loss。
重要性采样:Importance Sampling (IS),我们可以从中提取样本来估计任何已知函数L的。即:
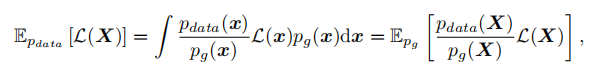
似然比/被称为重要性权重。
Adversarial Importance Weighting:在最优判别器的情况下延伸到一般情况下的权重。
在最优判别器下:越大,意味着权重越大,目标图像不太容易判别。在GAN中挖掘信息样本意味着找到hard假样本。
一般情况下:度量D和D*。首先通过预训练的embedding模型投影训练样本和生成结果到一个半径为r的超球面上,然后计算和欧式距离。定义和分别为类间距减去类内距的真实值和理想值。因此,AIW可表述为:
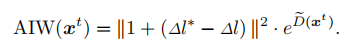
Multi-hop Sample Training:判别器通过AIW加强了,为平衡,让生成器多次翻译结果,这样属性多的就可以一步步实现。再加上MST,表达为:
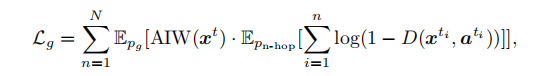
结构:
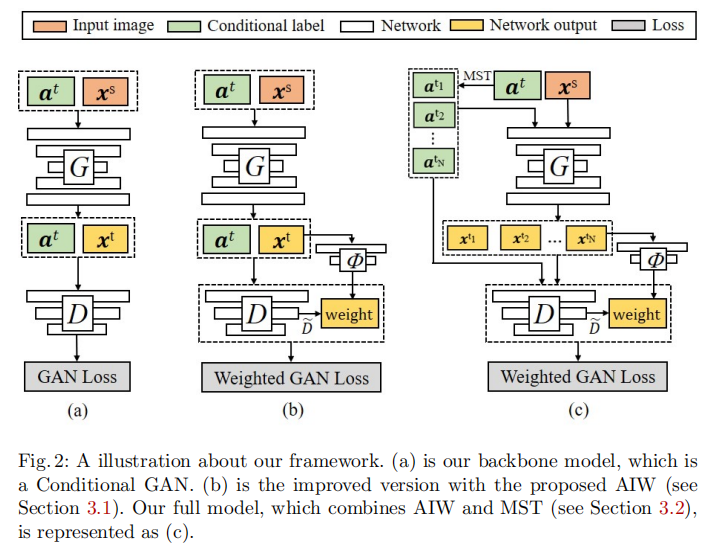
CGAN往上加,embedding模型为预训练的VGG,MST论文里取2-hop。
算法:

实验:人脸、季节、边缘等。其中多属性转移完成的很好。