阅读论文:GAN Compression: Efficient Architectures for Interactive Conditional GANs
GAN Compression,知识蒸馏,CVPR2020.
代码:https://github.com/mit-han-lab/gan-compression
问题:边缘设备内存少,计算慢。不能用CNN压缩方法原因:1.GAN训练不稳定。2.生成器结构不同。
损失:重构、对抗、蒸馏。
统一未配对和配对数据:即重构损失里(L1-norm),有监督用GT,而无监督用生成器的输出,分别与学生生成器的输出计算像素级差值。
继承教师判别器:仍使用教师判别器里的权重,并与学生生成器一起fine-tune学生判别器。随机初始化判别器会导致训练不稳定及图像质量下降等问题。
中间特征蒸馏:匹配教师生成器的中间表征,其中,G()学生生成器,G'()教师生成器,f卷积层(1x1)。
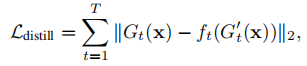
总损失:
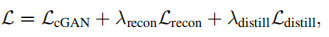
卷积分解和层灵敏度:采用卷积的分解形式(depthwise+pointwise)。然而直接用分解卷积会伤害图像质量,且层敏感度也不一样。因此,文中只分解resBlock层。
NAS自动裁剪通道:采用通道剪枝,减少通道数。每个卷积层从8的倍数中选取。
解耦训练和搜索:
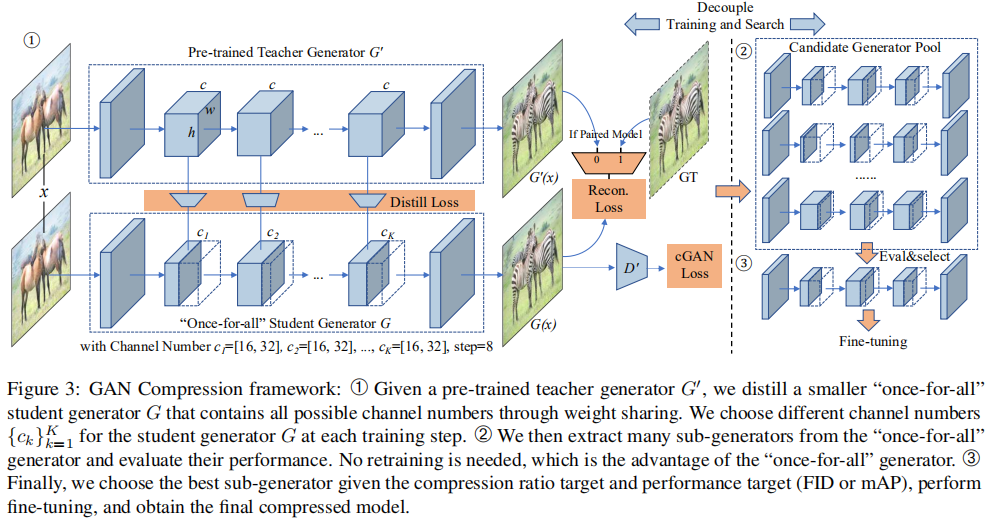
首先训练一个支持不同通道数量的"once-for-all"网络。不同通道数量的每个子网络都受到同样的训练,可以独立操作。子网络与“once-for-all”网络共享权重。

在每个训练步骤中,我们随机抽取具有一定通道数配置的子网络,计算输出和梯度,并使用我们的目标函数更新提取的权重。由于前几个通道的权重更新更频繁,它们在所有权重中起着更关键的作用。在“once-for-all”网络训练后,我们通过直接评估每个候选子网络在验证集上的性能来找到最佳的子网络。由于“once-for-all”网络是通过权值共享进行彻底训练的,因此不需要微调。 这近似于模型从零开始训练时的性能。这样,我们就可以解耦生成器体系结构的训练和搜索:我们只需要训练一次,但我们可以在不需要进一步训练的情况下评估所有可能的通道配置然后选择最好的一个作为搜索结果。 可选地,我们对选定的体系结构进行微调,以进一步提高性能。
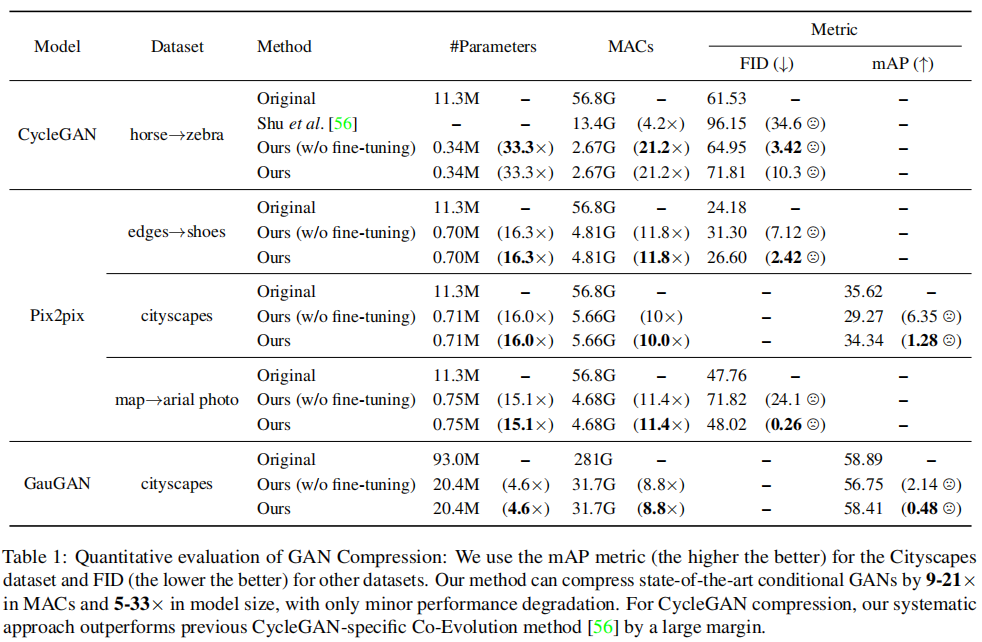
实验:模型:CycleGAN、pix2pix、GauGAN。数据集:Edges2shoes、Cityscapes、horse2zebra、map2aerial photo。
硬件:
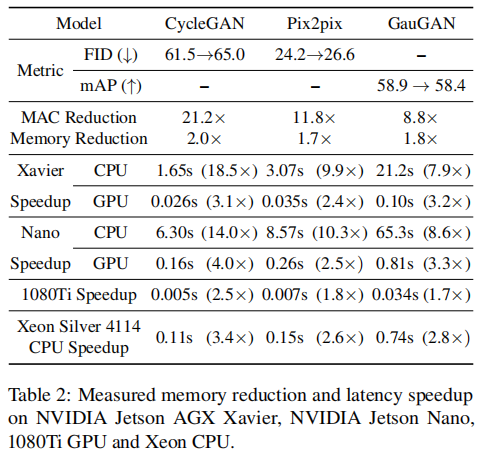
消融:无监督到有监督转换的优势,中间特征蒸馏和继承教师生成器的有效性,分解卷积的有效性。
未来方向:降低模型延迟和高效的生成视频模型架构。