阅读论文:Distilling portable Generative Adversarial Networks for Image Translation
知识蒸馏,AAAI2020。
问题:参数多,但不能直接用分类和目标检测中的压缩方法到GAN网络中。
原因:1.参数太多,不知道多余的是哪个。2.没有Ground Truth。3.GAN和CNN结构不同(有生成器和判别器),训练机制不同。
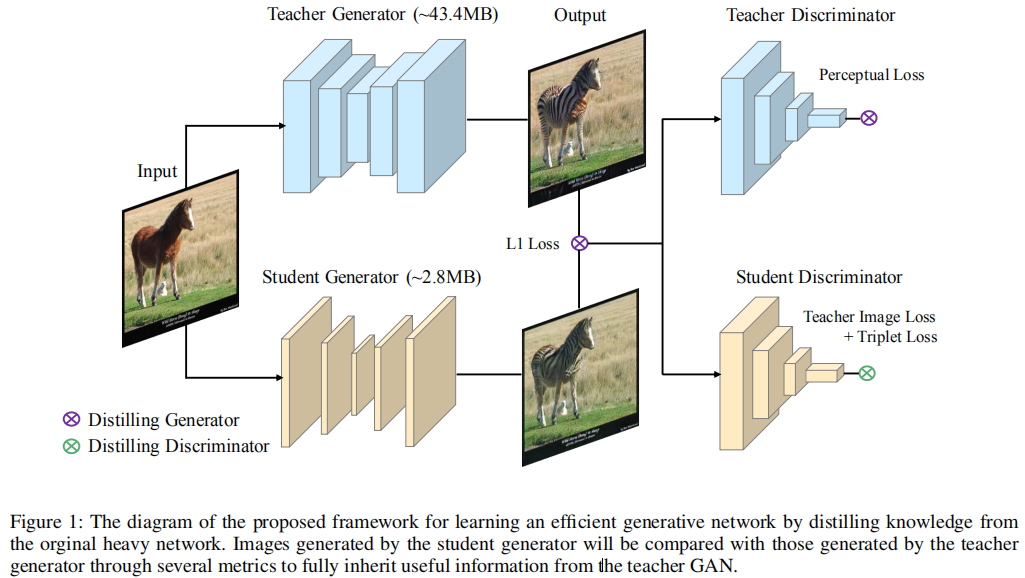
架构:
总损失:
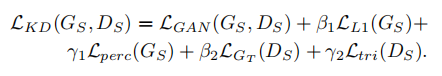
教师生成器和学生生成器生成图像间的像素级损失:
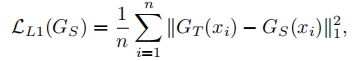
但上述会造成模糊,于是加入感知损失,但不同于用VGG-19提取特征,这里是教师判别器的前几层。
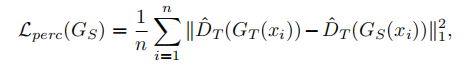
蒸馏学生判别器:将教师判别器的生成结果也作为True。
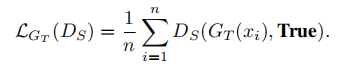
Triplet loss:教师生成器生成的图像与真实图像之间的距离应小于真实图像与学生生成器生成的图像之间的距离。
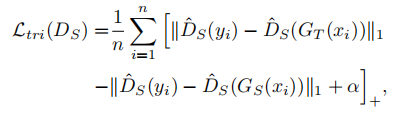
[·]+ = max(·, 0),是学生判别器移除最后一层。该公式的优点是鉴别器可以为真实样本构造一个比传统损失更具体的流形,然后生成器将获得更高的性能在更强的鉴别器的帮助下。
算法:

实验:语义图-真实图(Cityscapes),斑马-马等等。学生生成器大概为1/2或1/4的教师生成器的通道数即可。
定量:FCN-scores(Per-pixel acc. &Per-class acc. &Class IOU)
消融:探讨损失的影响。