阅读论文:CVPR2021几种图像翻译
1.Spatially-Adaptive Pixelwise Networks for Fast Image Translation
ASAPNet,优势:速度快,像素级网络。
代码:https://tamarott.github.io/ASAPNet_web
首先,像素级网络的参数在空间上是有变化的,因此它们可以表示比简单的1×1卷积更广泛的函数类。其次,这些参数是由一个快速卷积网络预测的,该网络处理输入的积极的低分辨率表示。第三,我们通过连接空间坐标的正弦编码来增强输入图像,这为生成真实的新型高频图像内容提供了一种有效的感应偏差。
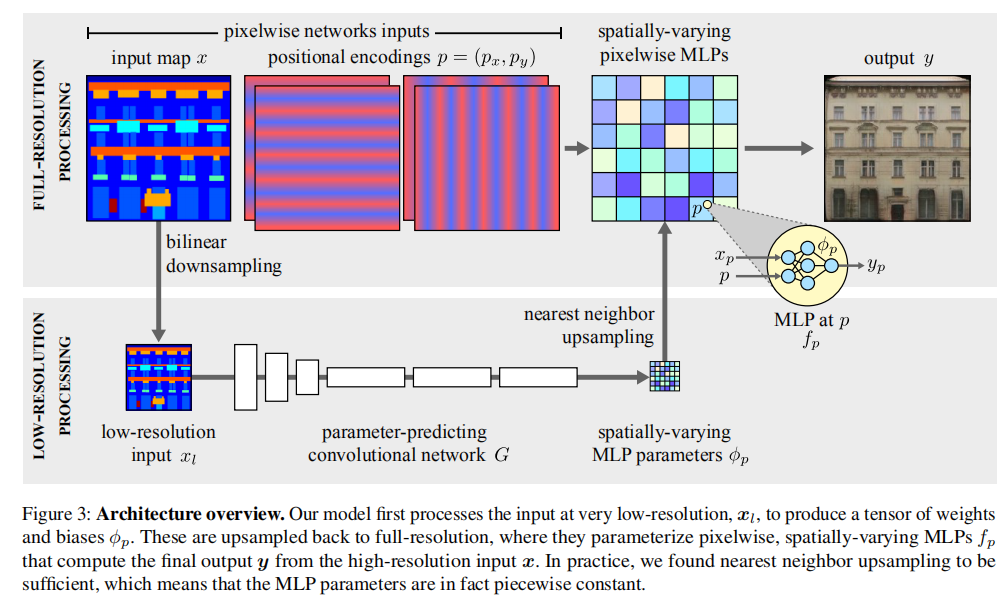
空间自适应像素级网络:
输入:像素坐标p,和它的颜色值。像素函数用空间变化的参数进行参数化,并以输入图像x为条件。f是MLP结构,是MLP的空间变化的权重和偏差。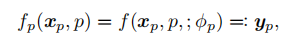 从低分辨率的输入中预测按像素化的网络参数:在低分辨率图像上通过卷积网络预测参数向量。最后再使用最近邻上采样方法恢复。在这个过程中,是一些卷积层,进一步降低空间维度S2=16倍(固定)。从高分辨率到低分辨率是采用双线性降采样,使分辨率减少S1倍。因此,总降采样S:=S1xS2。低分辨率图像必须在256x256以下。
从低分辨率的输入中预测按像素化的网络参数:在低分辨率图像上通过卷积网络预测参数向量。最后再使用最近邻上采样方法恢复。在这个过程中,是一些卷积层,进一步降低空间维度S2=16倍(固定)。从高分辨率到低分辨率是采用双线性降采样,使分辨率减少S1倍。因此,总降采样S:=S1xS2。低分辨率图像必须在256x256以下。
使用位置编码来合成高分辨率的详细信息:
我们发现将二维像素位置p=(px,py)的每个分量编码为频率高于上采样因子的正弦向量是很有用的。具体地,除了像素值xp之外,每个MLP还消耗2×2×k个额外的输入通道:,py也类似。
损失:与SPADE类似,对抗损失(hinge),感知损失,判别器特征匹配损失。
数据集:CMP Facades,Cityscapes, NYU depth dataset。
2.Image-to-image Translation via Hierarchical Style Disentanglement:
HiSD,层次风格解缠,可控多标签和多样式(多模态)。
代码:https://github.com/imlixinyang/HiSD
tags 和attributes 。
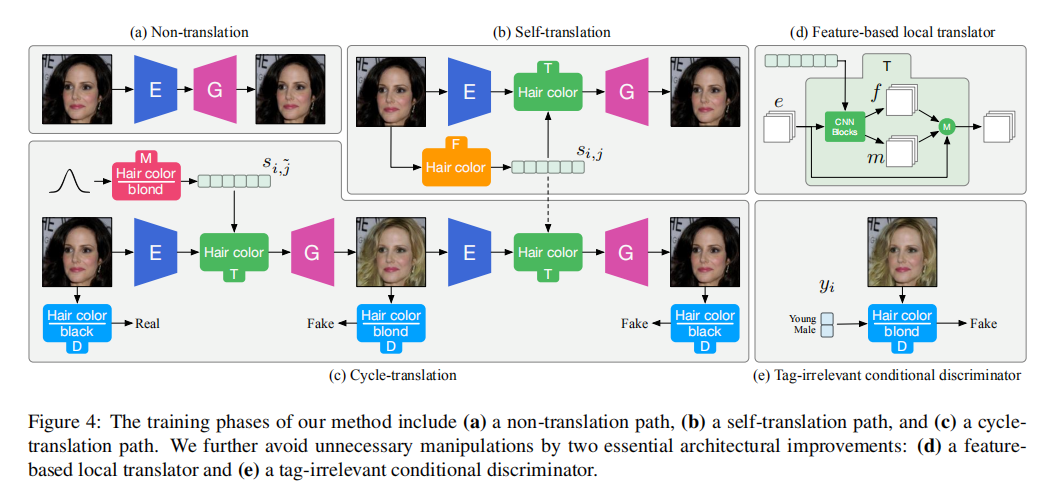
训练阶段:
非翻译路径:第一次重构。
自翻译路径:第二次重构。
循环翻译路径:首先生成与目标标签相关的样式代码;然后,得到翻译后的图像;最后,得到第三次重构的原图像。
目标函数:对抗损失,重构损失,样式。
对抗损失: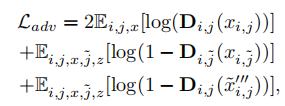
重构损失: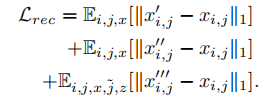
样式: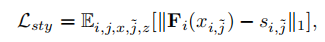
基于特征的局部翻译器:是注意力掩膜,这种设计可以避免背景和照明等全局操作,可以忽略额外计算,没有正则化目标。
与标签无关的有条件鉴别器:
对于不同的属性,隐式条件的不平衡现象在现实数据集中广泛存在。通过注入与标签无关的条件到判别器中来解决这个问题,即: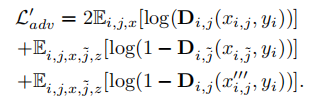
多样式任务,多属性任务,多标签任务的测试路径: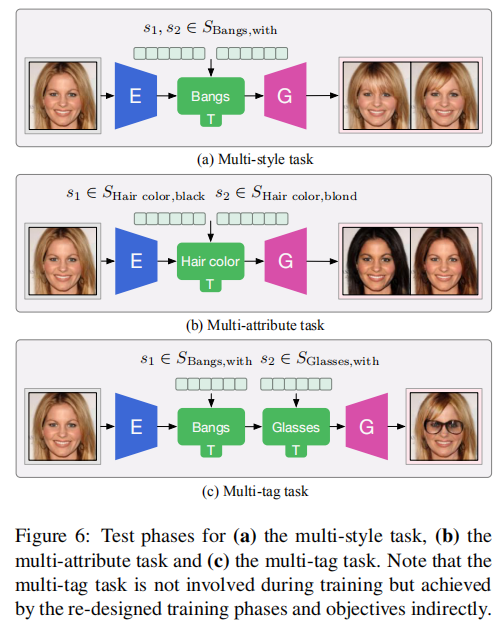
baseline:SDIT(带有共享风格)、StarGANv2(带有混合风格)和ELEGANT(带有特定标签的风格)。
CoMoGAN: continuous model-guided image-to-image translation:
CoMoGAN,连续I2I,无监督
代码:https://github.com/cv-rits/CoMoGAN
功能实例规范化FIN: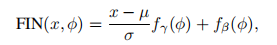
学习转换和的分布。
线性FIN参数: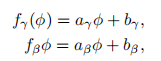
循环FIN参数: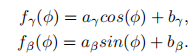
解缠残差块(DRB):
目标域和模型域组成:共有建模特征和私有非建模特征。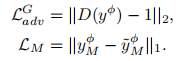
成对回归网络(-Net):
为了实现真正解缠,加强真实目标域图像和建模目标域图像之间的一致性,输入成对图像到一个CNN(-Net)中,回归它们的差异。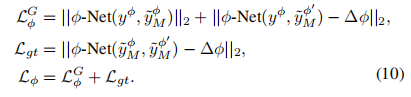
训练策略:
生成器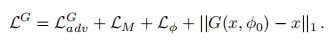
判别器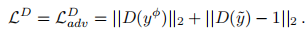
循环一致性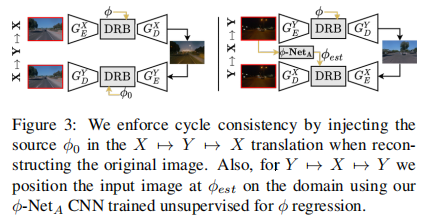
实验: day/dusk/night/dawn,iPhone→ DSLR,合成清晰→真实清晰,有雾
ReMix: Towards Image-to-Image Translation with Limited Data:
ReMix,数据少,数据扩增。
问题:GAN训练需要大量数据,若是较少,容易过拟合。
框架: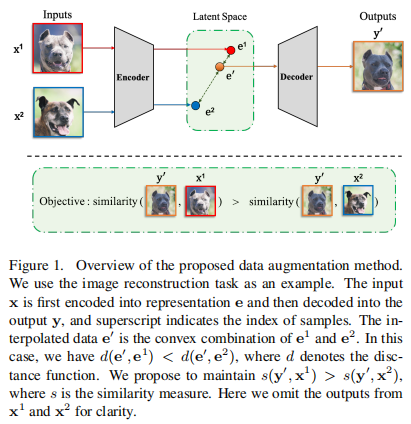
示例: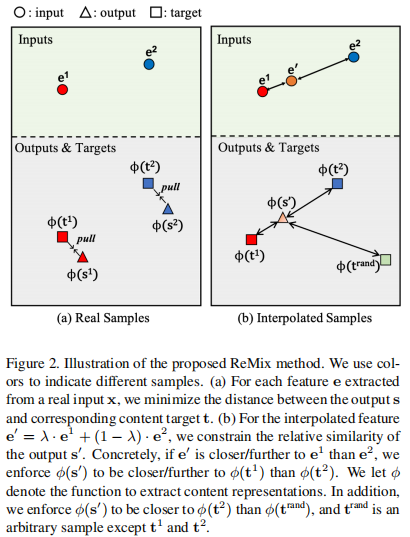
损失:是提取内容表征的函数。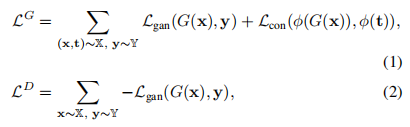
基于插值的数据增强:根据输入之间的感知关系来约束输出的相对位置,且是多模态的。
若是e1权重更高,有: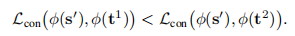
但是对于任意其它输入,e2更相近,即: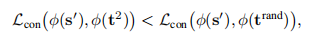
有限数据学习GAN模型:
计算插值权重: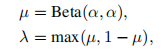
相对形式: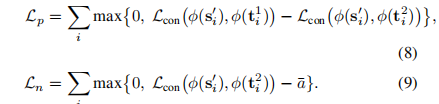
更新方式:初始化为0,然后计算a(j不等于i),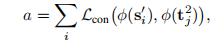
更新: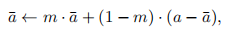
算法:
与已有方法比较:
已有方法估计对应的目标。比如:
或是利用正则化,噪声注入,最近邻插值。