阅读论文:Cross-Domain Cascaded Deep Translation
问题:无监督翻译里大多解决的是风格和外观的转换,本文考虑形状的转换。
两个域的语义相同,但外观和形状不同。一般来说是深层结构,浅层细粒度。
因此,论文在分类和图像翻译之间应用迁移学习,通过一个预训练分类网络提取编码的深层特征来学习翻译高级语义。不再是图像之间的翻译,而是特征之间的翻译。
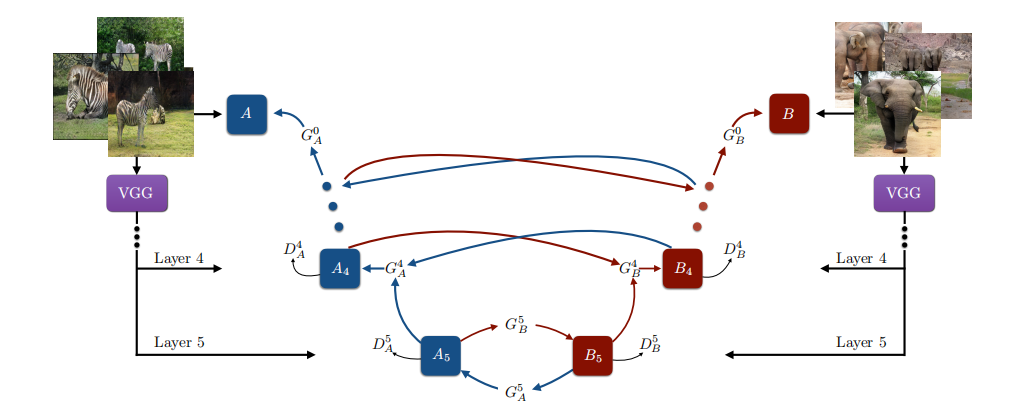
方法:deep-to-shallow
预处理:VGG-19提取5层采样特征,并归一化。
推理:逐级翻译,最后通过特征反演来获得最后图像。
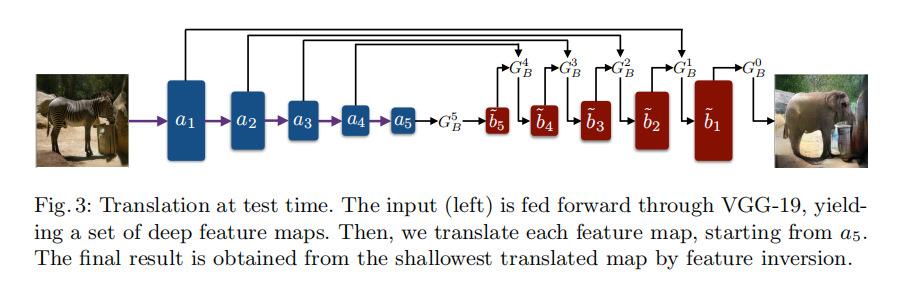
特征反演:通过预训练一个深层特征反演网络来可视化特征成图像,follow论文:Generating images with perceptual similarity metrics based on deep networks.
最深层翻译:CycleGAN,对抗损失(WGAN-GP),循环一致性损失,identity loss。
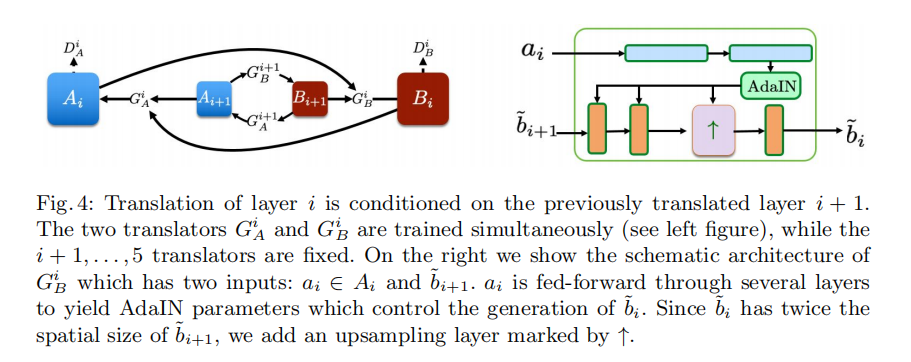
coarse-to-fine的条件翻译:AdaIN。如图,ai来生成每层的AdaIN参数,从而控制bi+1到bi的生成。
实验:斑马到大象,斑马到长颈鹿,差别都挺大。
将原始图像和生成图像经过VGG,提取最后一层全连接层,使用t-SNE投影向量(4096)到2D。

限制:1.不保留背景(因为一起编码了) 2.丢失小物体(VGG-19一般不可逆,且只能在有限类别分类) 3.翻译的小错误可能放大
验证该方法在无条件生成是否有用。(DEEP-VAE)