阅读论文:CR-GAN: Learning Complete Representations for Multi-view Generation
CR-GAN,多视角,自监督,2018
代码:https://github.com/bluer555/CR-GAN
多域图像生成的挑战:1)计算机需要想象3D旋转后的样子。2)多域生成需要保留共性。
单通道设计的问题:1)仅学习不完整的表征。2)对“看不见的”或无约束的数据产生有限的泛化能力。
单路和CR-GAN:单路仅是Z的一个子空间。没见过的就生成的不好。
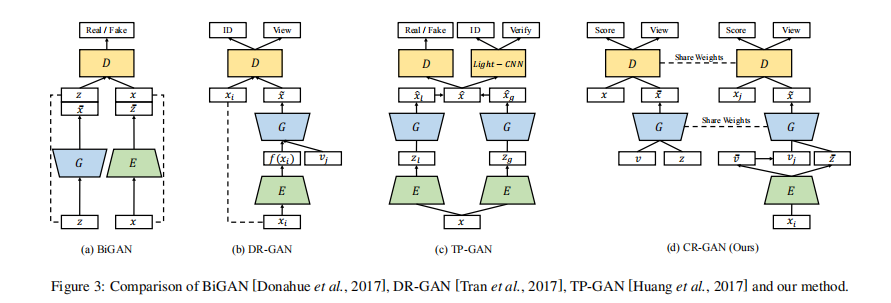
生成路径:训练G和D。E不参与。G学习如何从隐空间中的任意输入生成真实图像。
重构路径:训练E和D,保持G固定。G保留生成能力。

自监督学习:关键思想是使用预先训练的模型来估计未标记图像的视点。在第一阶段,对标记数据进行网络预训练,使E成为一个很好的视图估计器。在第二阶段,同时使用已标记和未标记的数据来提高G。

优点:1)它为视点估计提供了一个更好的预训练模型作为副产品;2)它保证了我们可以在训练中充分利用未标记的数据,因为CR-GAN学习完整表征。
对比方法:BiGAN,DR-GAN,TP-GAN
数据集: Multi-PIE,300wLP, CelebA,IJB-A